Machine learning algorithms generally assume the training and test distributions to be similar to learn predictive function of the test distribution. However, in many real world situations this condition fails and furthermore due to the lack of sufficient labels model parameters cannot be estimated. In such cases, information that is available from related known sources can be adapted (or) augmented to learn the predictive function for which the labels are scare. As the available source information and the target distributions to be learned follow different distributions, the traditional learning methods cannot be used. Transfer learning methods are adopted to obtain a learner for the distribution which is different from the available sources. This is done by instance based, feature based and parametric approaches. Target model parameters are learned by finding the distribution relevances from each source and target distributions. The distribution relevant measures are used to weigh the sources appropriately to model the target learner. Domain adaptation is an aspect of transfer learning when the feature spaces are the same and the marginal probability distributions are different between source and target domains. One can take advantage of the available multiple sources and learn the labels of the target domain as shown in the following figure.
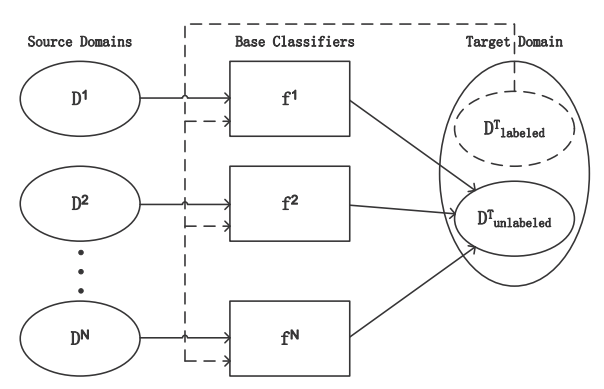
Domain Adaptation approaches enable transferring knowledge obtained in learning a particular task(s) and using (transferring) that knowledge to learn a new task which belongs to a different domain, in which tasks are related but with slightly different data distributions. This is achieved by minimizing both the marginal and conditional differences of the source and target data distributions.
Some of the applications that benefit from domain adaptation applications are Sentiment Classification, Email spam classification, Wifi localization, Remote Sensing change detection. etc